Downloading Llama2 from hugging face

For the current project I'm working on, I'm trying to fine-tune the retriever in a RAG pipeline using the Arcee/DALM repo. This requires passing in Meta's Llama2-7B model as the generator that is used in the fine-tuning process. Here are the steps in case it helps anyone!
Step 1: Get approved by Meta to access Llama2
On hugging face, you will see a notice as follows:
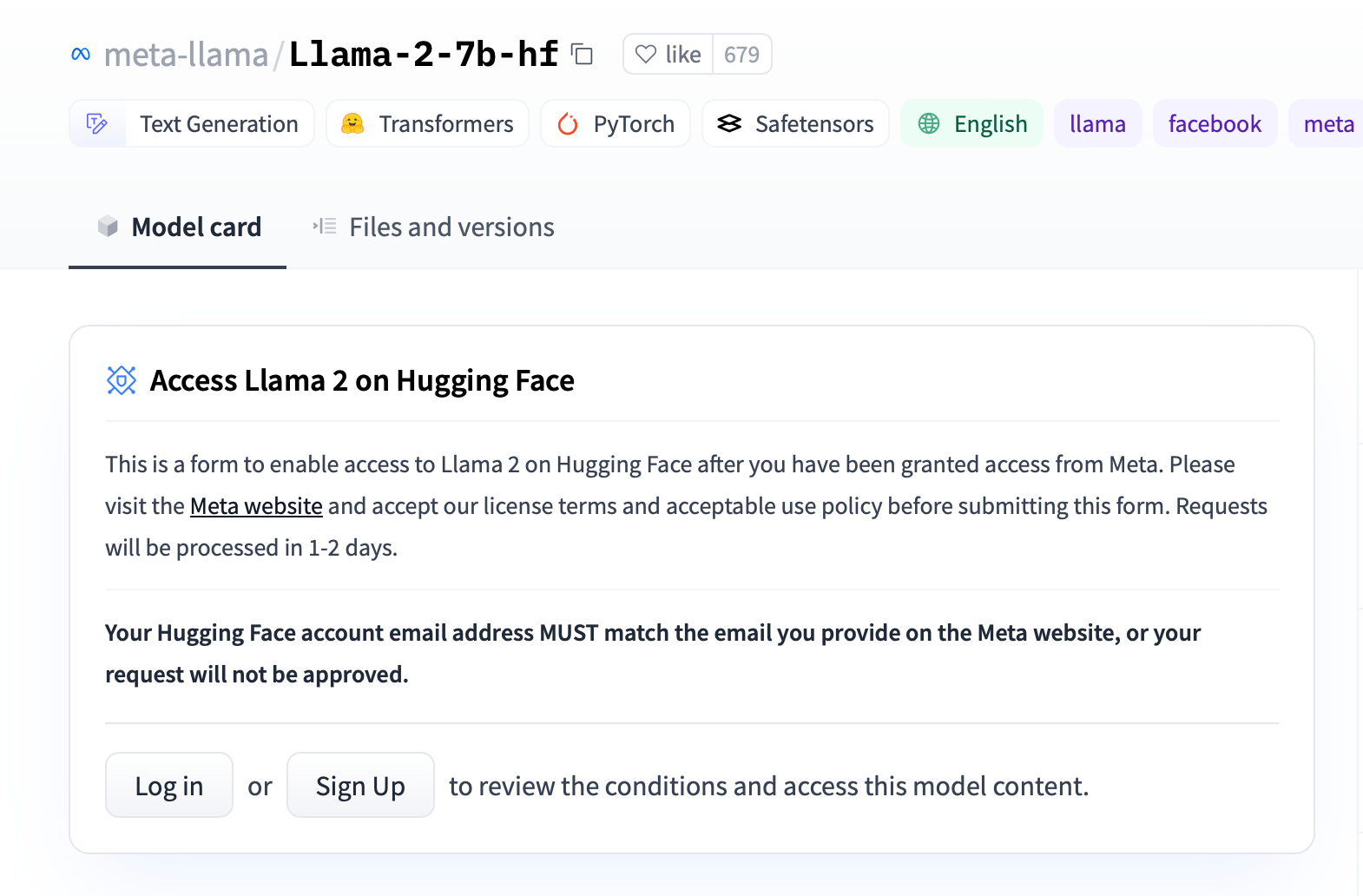
As it mentions in the instructions, you need to:
- Follow the link to the Meta website and fill out their form
- Create a hugging face account
- Submit the request to use the model
Once you do so, your model card will change to this:

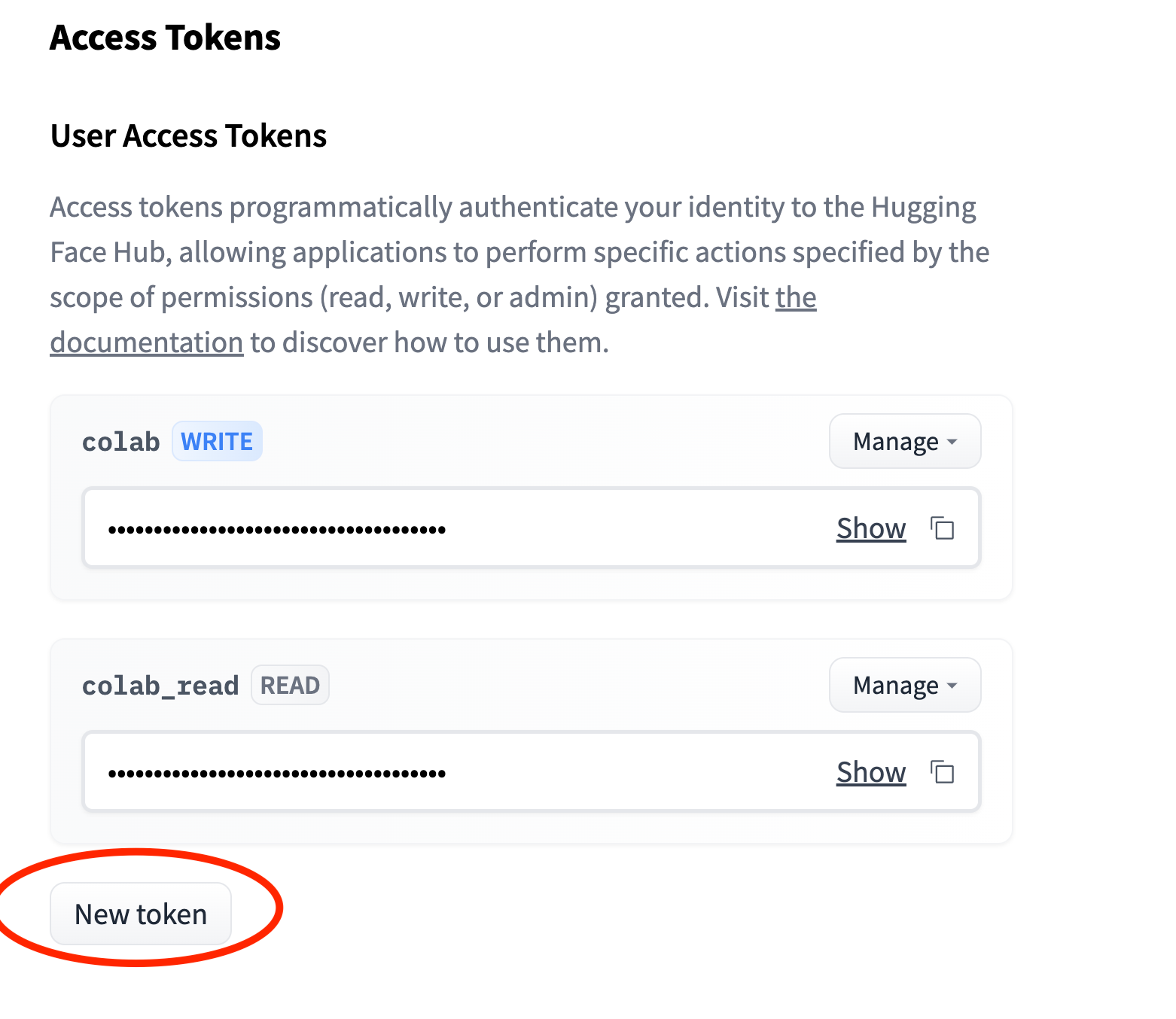
Step 2: Create a hugging face access token
On the hugging face access tokens page, create a new token. To download models, you only need to grant read access.
Step 3: Install git-lfs
This is needed for git large file support:
$ apt-get install git-lfs
$ git lfs installStep 4: Git clone the repo
This part is adapted from the original HF instructions, which assume you already have a repo, but why would you already have a repo if you haven't downloaded the repo yet?
Here's what I did:
$ mkdir llama2-7b; cd llama2-7b
$ git init .
$ git remote add origin https:<hf-username>:<hf-token>@huggingface.co/meta-llama/Llama-2-7b-hf
$ git pull origin mainReplace <hf-username> and <hf-token> with your actual hugging face username and token created above.
In my case, there was a warning in the output, but I didn't bother investigating
From https://huggingface.co/meta-llama/Llama-2-7b-hf
* branch main -> FETCH_HEAD
Filtering content: 100% (6/6), 9.10 GiB | 19.48 MiB/s, done.
Encountered 2 file(s) that may not have been copied correctly on Windows:
pytorch_model-00001-of-00002.bin
model-00001-of-00002.safetensors
See: `git lfs help smudge` for more details.Step 5: Load the model from the local file
First you will need to install hugging face transformers:
$ pip install transformers
Now you can start a python shell and load the model from the local llama2-7b directory created above:
Python 3.11.6 | packaged by conda-forge | (main, Oct 3 2023, 10:40:35) [GCC 12.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained('.')
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [01:15<00:00, 37.89s/it]In my case it took a few minutes to just load the model from disk since it's so large. But at this point, the model is ready for inference!
It's also possible to download the model directly from code instead of using git, but I couldn't find any simple examples of that.
Alternative approach: Download from code
Instead of using git to download the model, you can also download it from code.
Alt step 1: Install the hugging face hub library
$ pip install --upgrade huggingface_hub
Alt step 2: Login to hugging face hub
Login to hugging face hub using the same access token created above
huggingface-cli login --token $HUGGINGFACE_TOKENAlt step 3: Download the model
Start a python shell and run the following code:
Python 3.11.6 | packaged by conda-forge | (main, Oct 3 2023, 10:40:35) [GCC 12.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="meta-llama/Llama-2-7b-hf")
...
/home/ubuntu/.cache/huggingface/hub/models--meta-llama--Llama-2-7b-hf/snapshots/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9It will output the directory where the model was downloaded.
Alt step 4: Load the downloaded model
Start a python shell and load the model from the model download directory.
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained('/home/ubuntu/.cache/huggingface/hub/models--meta-llama--Llama-2-7b-hf/snapshots/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9')Now the loaded model is ready for use.
If you have any suggestions or questions, leave them on this twitter thread!