Building a PDF chat tool: A Technical Deep Dive

Recently, our team at Lazy Consulting embarked on an exciting project: constructing a web tool that enables interaction with PDF documents via LLMs.
First, a quick demo!

Requirements
We set out to build something that would meet the following requirements:
- Enable uploading of custom documents (PDF format only)
- Facilitate users in querying the documents in natural language
- Highlight relevant document sections that contributed to the response
- Provide a structured, domain-specific summary (focused on insurance)
Non-requirements
And decided to skip a few things for now:
- Conversational memory
- Streaming responses
Tech stack
- Langchain (Python-based)
- Python Flask REST API
- React/Next.js/TailwindCSS front-end
The choice between using the Langchain Python API vs the Typescript API had some tradeoffs. Using the Typescript API would have had the advantage of much easier integration into a Next.js application, however according to this Reddit thread the Langchain Typescript API is not at parity with the Python API.
Question answering
The first step with Retrieval Augmented Generation (RAG) is chunking and storing the uploaded PDF into the vector store.
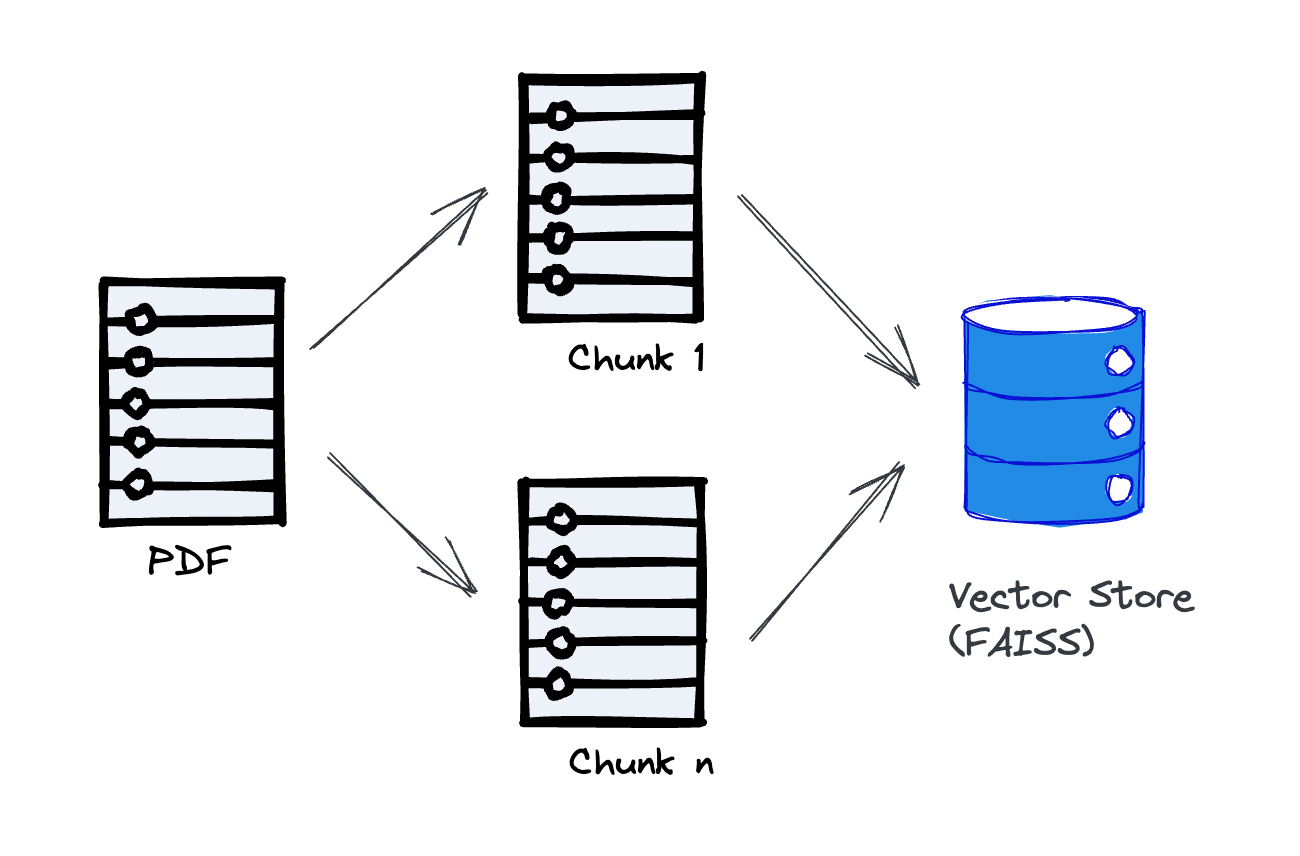
Here's the langchain code snippet that breaks the document into chunks and stores them in the vector store:
# Break into chunks
chunk_size_chars = 1000
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size_chars,
chunk_overlap=200,
length_function=len,
)
chunks = text_splitter.split_text(text)
# Create an embeddings helper
embeddings = OpenAIEmbeddings()
# Convert chunks into embeddings and store in the vector store
vector_store = FAISS.from_texts(
chunks,
embeddings
)This assumes you're using an OpenAI LLM, otherwise you would need to use a different embeddings helper.
Caching embeddings
Creating embeddings can be costly in terms OpenAI API costs. It is also one of the bottlenecks of the application due to the computational overhead, especially on large documents. Caching these embeddings in a pickle file can help here.
A few points to consider when caching embeddings:
- Relying solely on the filename as a cache key can be problematic, because it's possible for multiple users to upload documents named "contract.pdf" that differ in content. A more reliable method would be hashing the file and appending that hash to the cached embeddings filename.
- Ensure that your caching approach accounts for all pertinent embedding characteristics, such as chunk size and the embeddings helper in use.
Running the chain
Here's the high level overview of the chain:
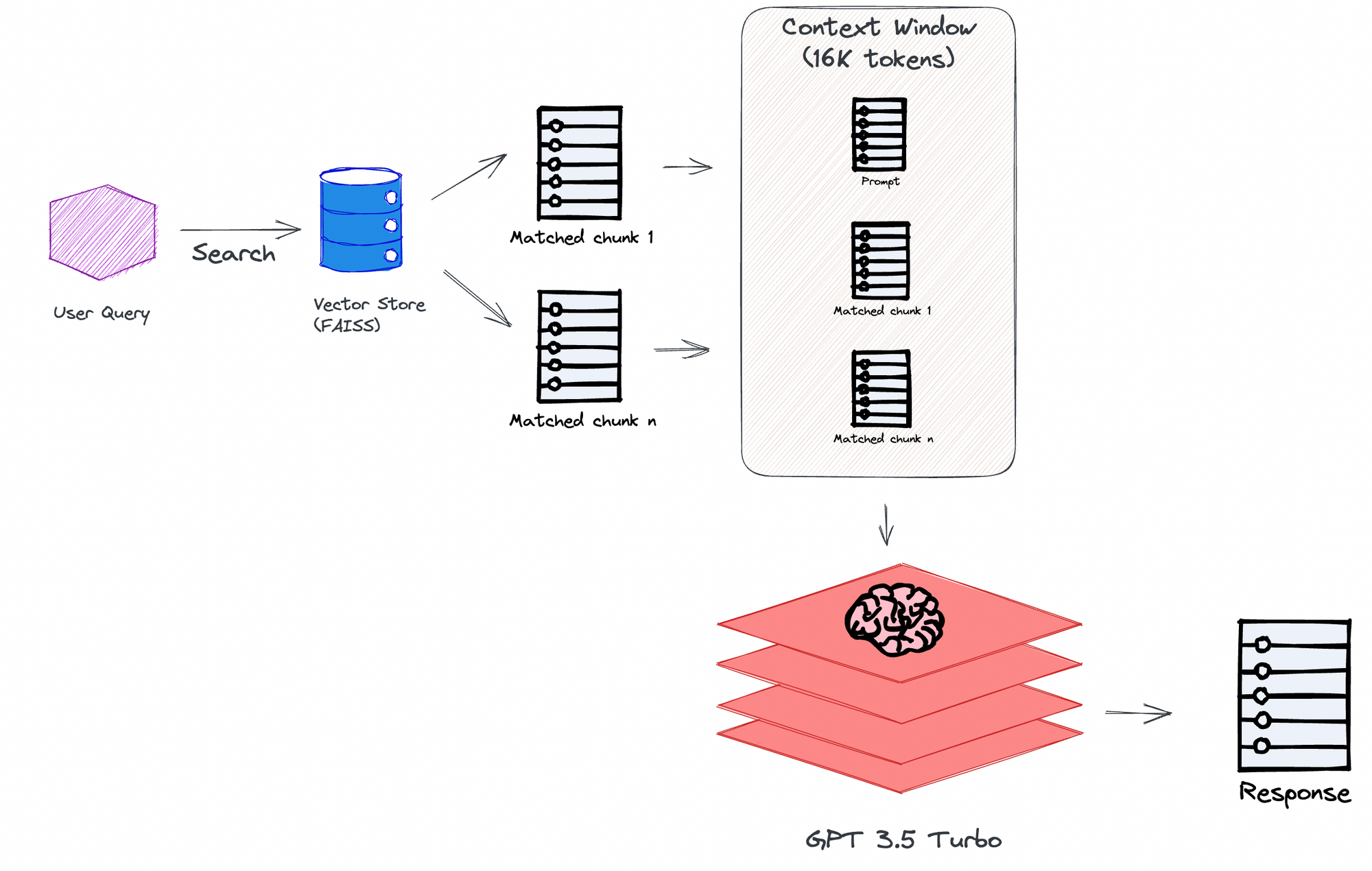
Having already created the vector store for a specific document, the system matches the user's query against it to identify chunks that are semantically similar. Here the "user query" refers to the text entered into the search box, such as "How much personal liability is covered by this policy?"
Next, the system populates the 16K context window with as many matched chunks as possible, along with the prompt template. The system uses the tiktoken Python library to tokenize the document, enabling it to determine the total token count. Using this data, the system estimates the number of tokens in each chunk and in the prompt. This estimation helps in calculating the number of chunks that can be included in the total prompt text sent to the LLM.
Showing relevant document sections
Since LLMs are sometimes known to produce inaccurate or imaginative outputs (aka "hallucinating"), showing the relevant document sections helps users verify the response from the LLM.

To enable this functionality, the system invokes the similarity_search_with_score() method provided by the FAISS library and returns the top scoring results to the front-end.
Initial Summarization Approach: Evaluating the Entire Document
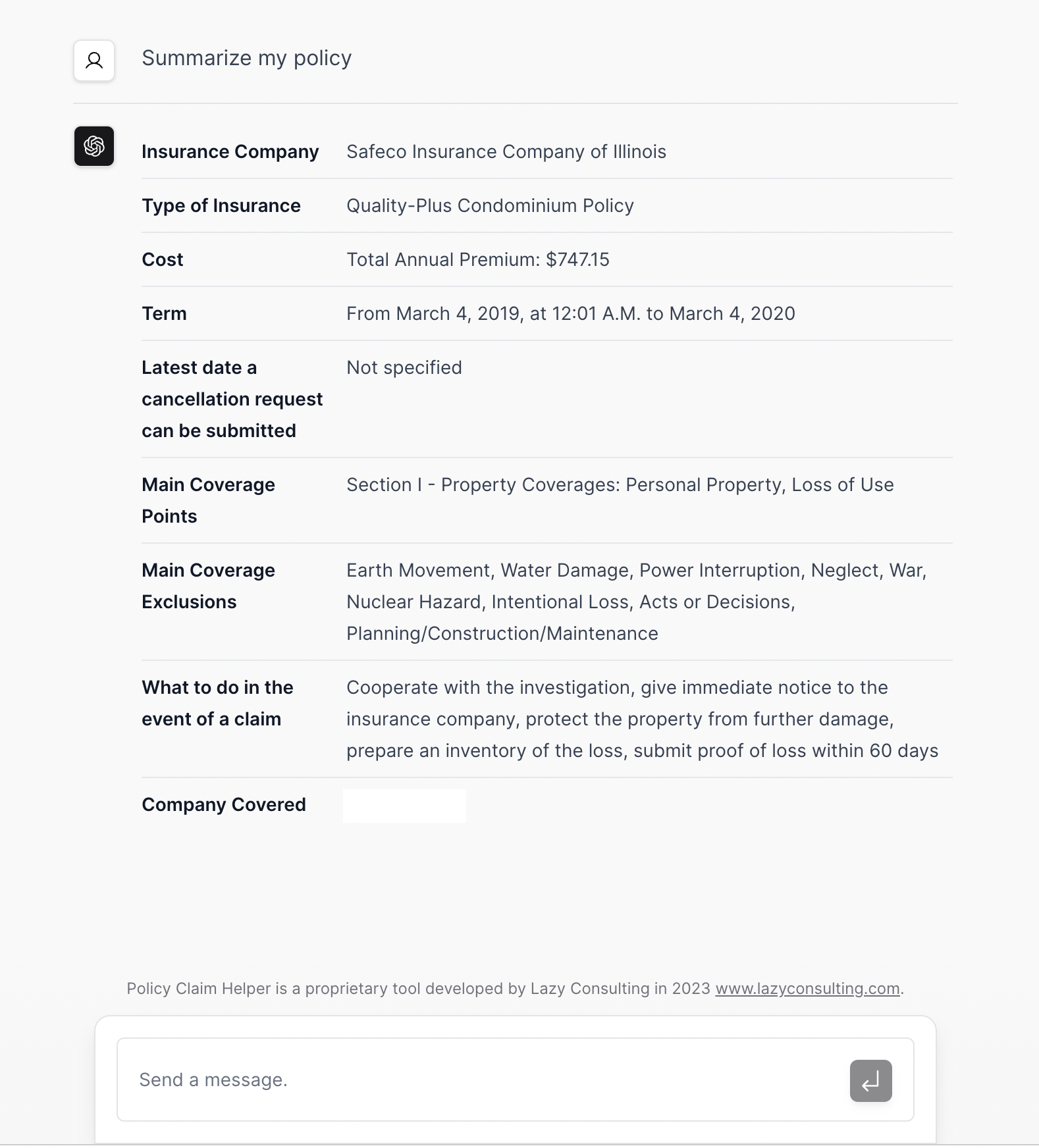
When a document fits in the context window, then a viable approach would be to use the langchain load_summarize_chain() method with the "stuff" strategy and include the entire document in the prompt.
However, if the entire document doesn't fit in the context window, then a more sophisticated approach is needed. While Retrieval Augmented Generation (RAG) is good for question answering, it is not really appropriate for summarization. Simply scanning the document for sections labeled "summary" or containing the word "summarize" might not yield the desired outcome unless the document distinctly features a "summary" section.
For a comprehensive summary, it is important to evaluate the entire document, and it is not safe to assume every document will fit within the context window. This is a great fit for strategies like map-reduce, so let's explore how that works.
Map phase

In the map phase, langchain will construct multiple calls to the LLM, each call containing as many chunks as it can fit into the context window.
It will use a specialized prompt for the partial summary. For example:
map_prompt_template_text = """
Summarize the following text:
{text}
SUMMARY:
"""For each call to the LLM, it will get back a partial summarization of those particular chunks.
Reduce phase
The next step is to summarize the partial summaries into a final summary.

Here's the reduce prompt we used for this application. Keep in mind this prompt is tailored for the particular requirement to provide users with a domain-specific and structured summary:
combine_prompt_template_text = """
Read the context and extract the following information.
Insurance Company
Type of Insurance
Cost
Term (Contract start and end date)
Latest date a cancellation request can be submitted
Main Coverage Points
Main Coverage Exclusions
What to do in the event of a claim
Company Covered (Our client's company name)
{text}
And provide a CONCISE SUMMARY as a non-markdown HTML table with table, tr, and td tags:
"""A quick aside: our initial attempts to produce a table by just saying "And provide a summary as an HTML table" did not work, as the LLM seemed to produce a markdown table. But giving the LLM a very specific requirement about the HTML table finally did the trick!
Here's the call to langchain with both prompts and using the map-reduce strategy and the custom prompts:
variables = ['text']
combine_prompt_template = PromptTemplate(
template=combine_prompt_template_text,
input_variables=variables,
)
map_prompt_template = PromptTemplate(
template=map_prompt_template_text,
input_variables=variables,
)
chain = load_summarize_chain(
llm,
chain_type='map_reduce',
combine_prompt=combine_prompt_template,
map_prompt=map_prompt_template
)Improved Summarization with RAG
Our initial approach to summarization gave very good results, but with large documents it was taking well over 60 seconds due to the multiple round-trips to the LLM. For this application, there was a hard-limit to keep the responses under 30 seconds, so we needed to improve the approach.
For this particular application, the summarization is essentially a series of questions along with their answers, so the same Retrieval Augmented Generation (RAG) approach that was used for question answering can be reused here. This will only have a single round-trip to the LLM so will be a lot faster.
Our key insight was to extract the summarization bullet point items from the prompt and use these to query the vector store:
query = """
Insurance Company,
Type of Insurance,
Cost,
Term (Contract start and end date),
Latest date a cancellation request can be submitted,
Main Coverage Points,
Main Coverage Exclusions,
What to do in the event of a claim,
Company Covered (Our client's company name)
"""
similar_chunks_with_scores = vector_store.similarity_search_with_score(
query=query,
k=num_similar_chunks
)This will find the document chunks that are related to one or more of these questions. Those chunks will then be included in the context for the combine_prompt_template_text above. Since map-reduce is no longer needed, the "stuff" chain can be used:
chain = load_summarize_chain(
llm,
chain_type='stuff',
prompt=combine_prompt_template
)
response = chain.run(similar_chunks)Ideas to Enhance the User Experience (UX)
Add conversational memory
As mentioned in the hwchase17/chat-your-data blog post:
Do you want to have conversation history? This is table stakes from a UX perspective because it allows for follow up questions.
Langchain offers a ConversationBufferMemory class to simplify the process.
As a downside, adding the conversation memory will take up some room in the context window. To stay under the context window limit, some of the matching chunks from the vector store would need to be discarded.
Streaming responses
Users expect a streaming response as the LLM generates tokens, similar to OpenAI's ChatGPT UX.
This would require changes in three places:
- Langchain calls to pass
streaming=Trueto the LLM (not all LLM's support streaming) - Flask response to use the
stream_with_context()function. - React front-end to use the browser's built-in
EventSourceobject.
Fix PDF extraction spacing issues
When showing the relevant document sections (the matching chunks from the vector store search), for some PDFs the whitespace has been removed:
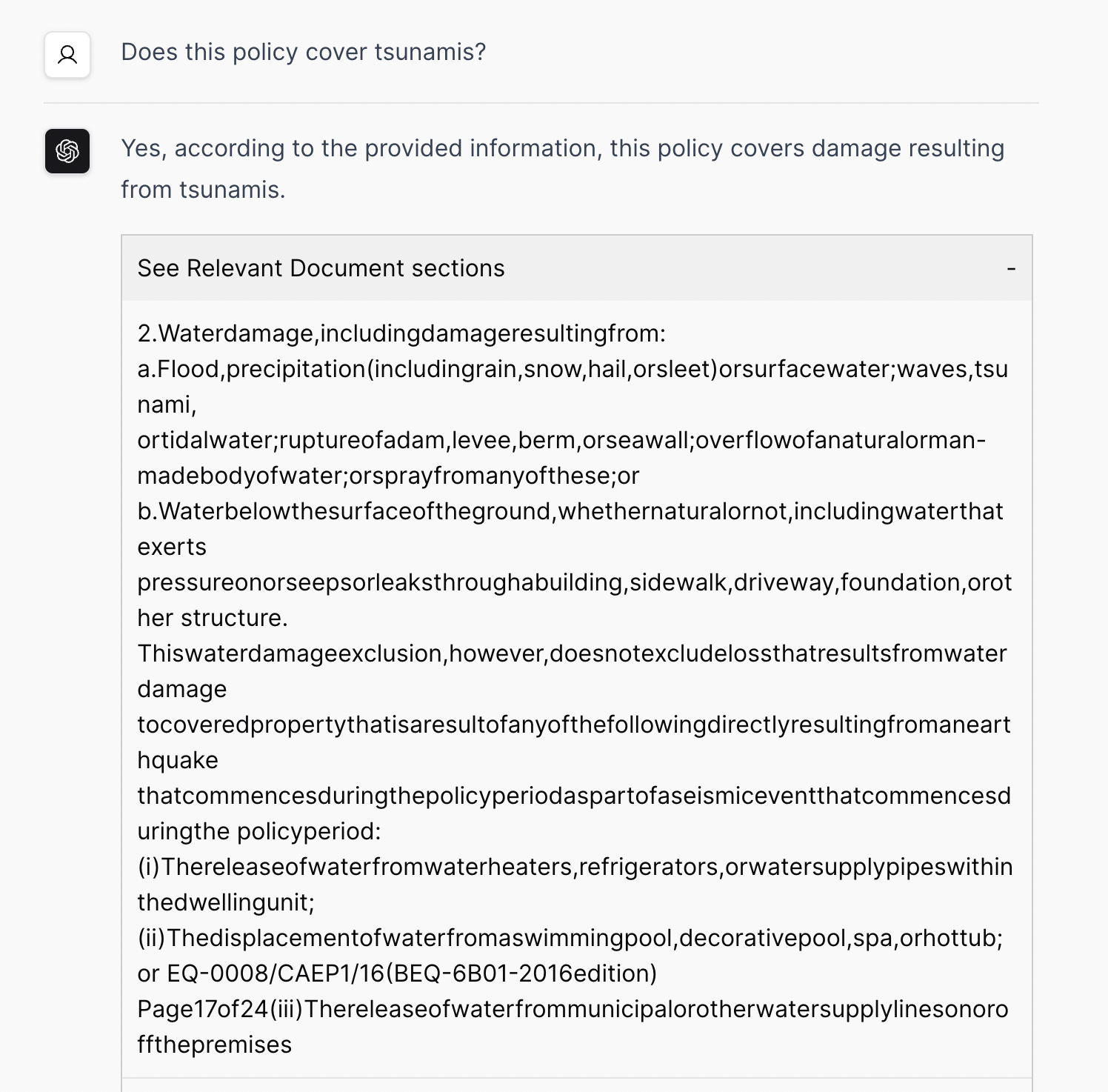
This seems like an issue with PyPDF - they have a list of known whitespace issues.
Keeping the LLM on topic
Ideally the app should decline to answer any questions not related to the document.
This should be possible to fix with some prompt engineering, as the current default langchain prompt apparently isn't specific enough:
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
Handle foreign languages better
In our testing we observed that the LLM always answers in English, regardless of the document source language and which language you used to ask the question.
A better behavior would be to detect the language was used in the question and use that for the resulting output. This might be possible by just giving an extra hint to the LLM in the prompt.
PDF Compatibility
During our testing, we noticed that text extraction was ineffective for certain PDFs, especially PDFs based on scanned images. Optical character recognition (OCR) should be leveraged to transform images into text when needed.
Ideas to improve the tech stack
Reduce dev costs via local hugging face or local models
To see how much the LLM calls are costing, you can use a LangChain callback to enable verbose output:
with get_openai_callback() as cb:
response = chain.run(similar_chunks)
print(f"OpenAI data: {cb}")
which will print out something like the following:
OpenAI data: Tokens Used: 13859
Prompt Tokens: 13407
Completion Tokens: 452
Successful Requests: 1
Total Cost (USD): $0.042029Yikes, 4 cents! With map-reduce and multiple round-trips to the LLM, this number could be much higher.
There are a few ways to avoid these unnecessary costs while testing:
- Use a free Hugging Face model via an API request (up to a certain limit on number of requests)
- Use an open source model running locally
When using a Hugging Face model, you will also have to switch the embeddings library from OpenAIEmbeddings to HuggingFaceEmbeddings.
An open source model requires more effort and possibly more compute resources. However if you have a mac with Apple Silicon, the GGML-based models such as TheBloke/Llama-2-7B-Chat-GGML should work well. Otherwise if you have an Nvidia GPU, check out the GPTQ-based models like TheBloke/Llama-2-7b-Chat-GPTQ. To wrap them up in an API that can be accessed from Langchain, OpenLLM or vLLM might be good starting points.
Explore other open source LLM frameworks
Langchain has worked well for us so far, at least on a small scale, but there are a few other really interesting looking open source projects that could also handle the same use-case:
Haystack in particular looks interesting, as they have optimized for scalability and also have a commercial cloud hosting option.
References
Here are some resources to help you build your own PDF chat app:
- DeepLearning.ai short course: 'Langchain chat with your data'
- Langchain "Chat Your Data" Github repository
If you found this post useful, give it a like or leave comments on Twitter. Thanks for reading and happy LLM hacking!