Tennis court line detector: Part 3, detecting non-visible keypoints


In part 2 we got a basic CNN trained to overfit the training data, but all of the training data showed all keypoints as being visible.
Generate images with non-visible keypoints
Let's make things a bit harder for the network and generate images where some of the keypoints are off the edge of the image boundaries, and therefore not visible.

In order to achieve that, position the camera in unity so that it is closer to the tennis court
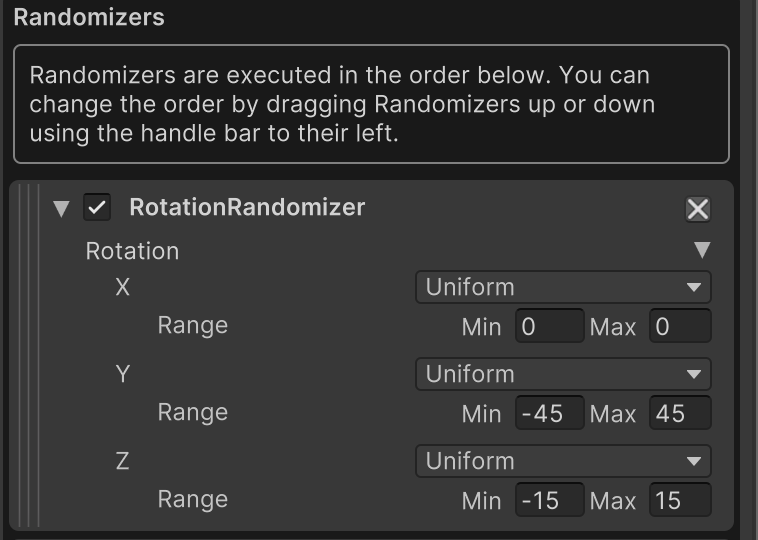
And use the following rotation randomizations when generating the dataset
Update the model to handle the visibility flag
In order for the model to be able handle the visibility flag, a categorical variable now needs to be predicted in addition to the existing continuous variables.
Because they are different types of variables, they each need their own loss functions:
- Continuous variables - MSE loss
- Categorical variables - Cross Entropy loss
Therefore, we can't share the same head for both types of variables, since each head needs its own loss function.
The 17 headed beast
My initial approach was to define a separate head for each keypoint to predict the visibility categorical variable associated with that keypoint. This results in a 17 headed beast!
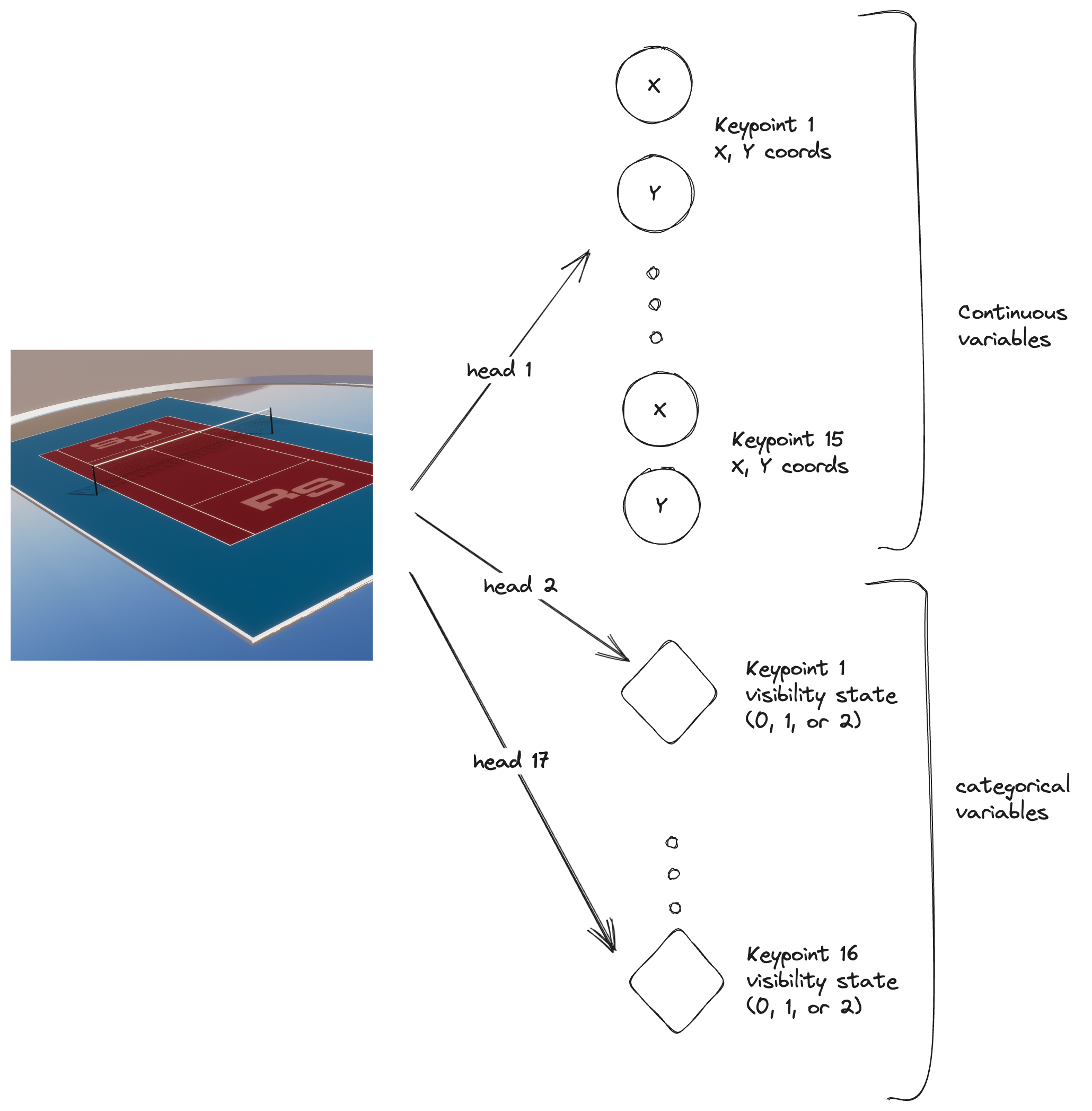
This worked, but the code was a bit unweildy.
class LitVGG16(pl.LightningModule):
def __init__(self, num_epochs):
super().__init__()
...
self.vgg16 = torch.hub.load('pytorch/vision:v0.6.0', 'vgg16', pretrained=True)
# Redefine the classifier to remove the dropout layers, at least while trying to overfit the network
self.vgg16.classifier = nn.Identity()
# Separate head for continuous output for the 16 keypoints
self.continuous_output = nn.Sequential(
...
)
# Separate head for categorical output for the 3 different states that each keypoint can have
self.kp0_state = nn.Linear(25088, 3)
self.kp1_state = nn.Linear(25088, 3)
...
self.kp15_state = nn.Linear(25088, 3)
def forward(self, x):
vgg_features = self.vgg16(x)
keypoints_xy = self.continuous_output(vgg_features)
kp0_state = self.kp0_state(vgg_features)
kp1_state = self.kp1_state(vgg_features)
...
kp15_state = self.kp15_state(vgg_features)
return keypoints_xy, kp0_state, kp1_state, ..., kp15_stateThe 2 headed beast
This can be simplified to 2 heads as follows:
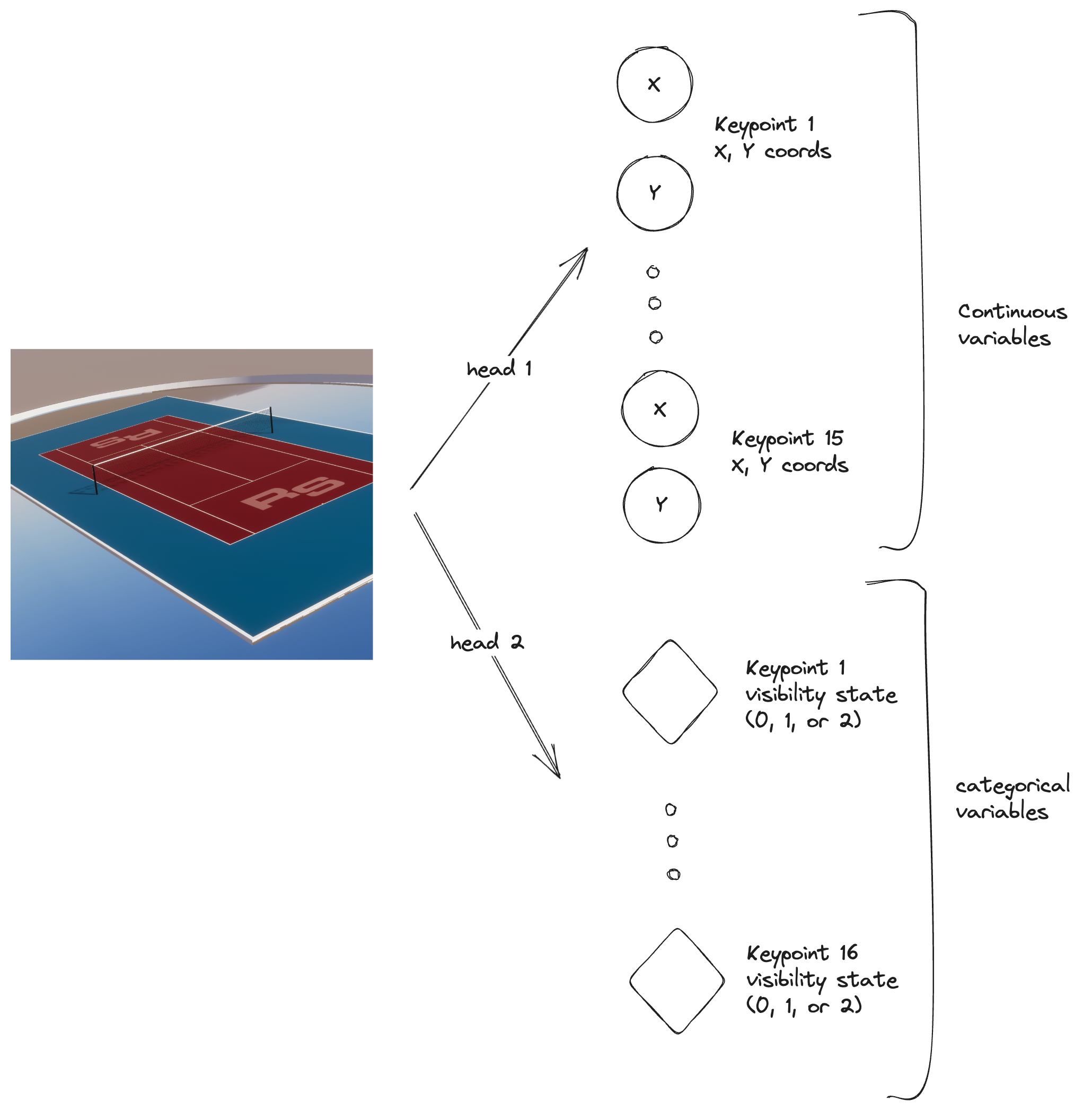
With the 2 headed approach, the inputs and targets need to be reshaped as follows
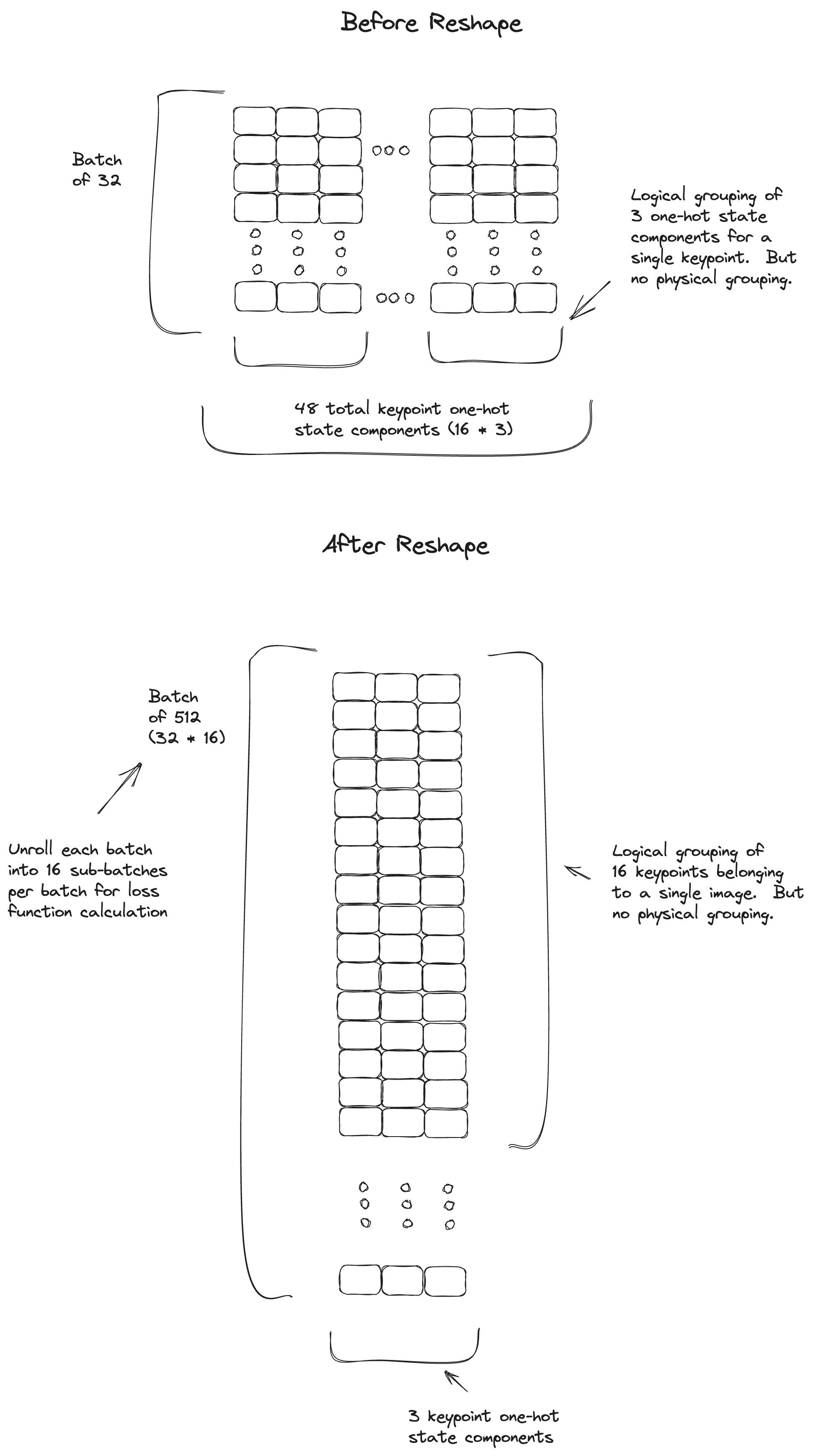
The full source code is available at https://github.com/tleyden/tennis_court_cnn
Re-run training
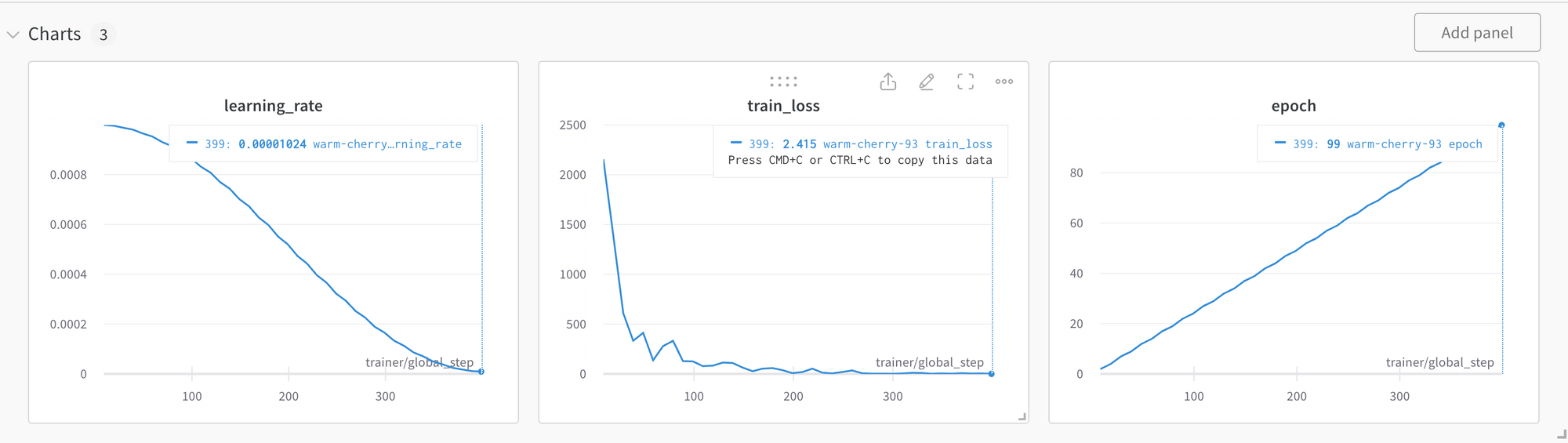
The total training loss ended up at ~ 2.0 after 100 epochs
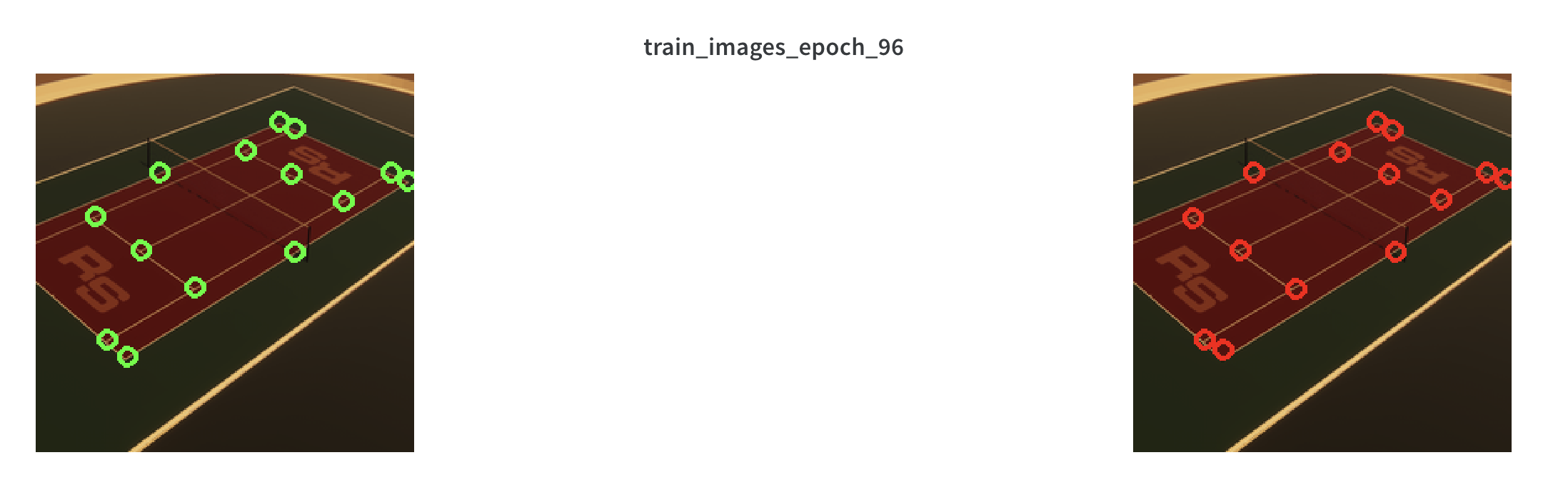
As seen here, the network can now predict both the X, Y coordinates of kepoints as well as whether a keypoint is visible or not.
Recap
So far we've:
- Generated a synthetic training dataset
- Overfit a model (no validation) on the training dataset
- Regenerate the synthetic dataset to have non-visible keypoints
- Updated the model to account for keypoint visiblity
- Retrained the model on the updated dataset (still no validation)
In the part 4, let's increase the variety of our dataset by adding more tennis courts and splitting the dataset into training, validation and test set splits.